As stated in the help. the operator uses the covariance matrix of the input attributes. Normalizing the attributes using the Normalize operator and Z-transformation method before the PCA operation has the effect that the correlation matrix is used in the PCA operator (As Wikipedia states, the correlation matrix can be seen as the the covariance matrix of the standardized variables).
Some small differences emerge in the calculated standard deviations in comparison with R's princomp function. I believe this is because the R function uses N-1 as the divisor when calculating standard deviations whereas RapidMiner uses N.
Sunday 29 December 2013
Tuesday 26 November 2013
New book: Exploring data with RapidMiner
I'm the author of "Exploring real data with RapidMiner"
Of course I would be very happy if you would like to purchase a copy :)
Some more details are here.
Of course I would be very happy if you would like to purchase a copy :)
Some more details are here.
Monday 18 November 2013
Negative and positive lags
It's often required to compare an attribute's value in one example with a value in another example either in the past or in the future.
The Lag Series is the one to use to get previous values brought forward to now. Looking into the future is somewhat harder (and of course you can argue that in a Data Mining context, it's cheating to use future values when these are the things we are trying to predict).
One approach is to go forward in time and use the lag operator to bring forward the values that are now in the past. Then go back in time and use the values brought forward as the new now.
Another approach is to use the Generate Id operator combined with the Join operator. There is a little known parameter called "offset" that allows numerical ids to be generated from a given starting value. If this operator is applied twice with different offsets (with some accompanying gymnastics to make the ids regular attributes with different names) followed by Join using these ids, the result is an example where past and future values can be brought to the present (although some more gymnastics are needed to get the names right).
Here's an example process showing this with the Lag Series operator for comparison (make sure you install the Series extension for the Lag Series operator).
Maybe those nice RapidMiner R&D chaps will add a negative lag :)
The Lag Series is the one to use to get previous values brought forward to now. Looking into the future is somewhat harder (and of course you can argue that in a Data Mining context, it's cheating to use future values when these are the things we are trying to predict).
One approach is to go forward in time and use the lag operator to bring forward the values that are now in the past. Then go back in time and use the values brought forward as the new now.
Another approach is to use the Generate Id operator combined with the Join operator. There is a little known parameter called "offset" that allows numerical ids to be generated from a given starting value. If this operator is applied twice with different offsets (with some accompanying gymnastics to make the ids regular attributes with different names) followed by Join using these ids, the result is an example where past and future values can be brought to the present (although some more gymnastics are needed to get the names right).
Here's an example process showing this with the Lag Series operator for comparison (make sure you install the Series extension for the Lag Series operator).
Maybe those nice RapidMiner R&D chaps will add a negative lag :)
Saturday 5 October 2013
Bulk export of processes
I am doing something at the moment which requires me to to export a load of processes contained in folders within a single repository to a single disk location. Rather than do it one by one which is error prone and time consuming, I decided to make a RapidMiner process to do the export.
It turns out that the files in the repository with the extension .rmp are valid xml files that can be imported so all I did was point a Loop Files operator at the folder where my repository was and looked for files ending in .rmp. Inside this loop, I used the Generate Macro operator to generate the new location and the Copy File operator to copy the file from the repository to the new location.
The location of the repository and the location where the files to be copied are defined in macros in the process context. Set these to the values you want. Note that on Windows machines it is necessary to use double backslashes to delimit folders.
The process is here.
It turns out that the files in the repository with the extension .rmp are valid xml files that can be imported so all I did was point a Loop Files operator at the folder where my repository was and looked for files ending in .rmp. Inside this loop, I used the Generate Macro operator to generate the new location and the Copy File operator to copy the file from the repository to the new location.
The location of the repository and the location where the files to be copied are defined in macros in the process context. Set these to the values you want. Note that on Windows machines it is necessary to use double backslashes to delimit folders.
The process is here.
Parsing macros with values containing backslashes
Let's imagine we are looping through some files and we happen to know that the files are buried somewhere in folders called chapterNN where NN is a number. How can we extract information about the location for each file individually?
Within a Loop Files operator, the parent_path macro would take values like this within the loop (I'm assuming Windows obviously).
c:\myGiantFolderStructure\mybook\chapter01
c:\myGiantFolderStructure\mybook\chapter02
...
c:\myGiantFolderStructure\mybook\chapter11
If we wanted to extract the last part of the folder name including the number to use in the loop we could try the Generate Macro operator with the replaceAll function.
The basic idea would be to configure the operator like so.
chapter = replaceAll("%{parent_path}", ".*(chapter.*)", "$1")
This matches the entire macro with a regular expression but locates the word "chapter" and whatever follows it inside a capturing group. This replaces the entire value of the parent_path macro. The result should be a new macro called chapter with values from chapter01 upwards.
Unfortunately, this doesn't work because the backslashes cause trouble. I'm guessing but I think the replaceAll function (and its siblings, replace and concat) try to parse the string within the macro and get confused by treating the backslash as an escape character.
Fortunately, there is a solution: a little known function called macro. This function simply returns the string representation of a named macro.
The expression would then look like this.
chapter = replaceAll(macro("parent_path"), ".*(chapter.*)", "$1")
Knowing that backslashes are processed enables to us work out how to pass them simply by escaping them. If we felt we needed a more sophisticated match inside the capturing group to ensure we picked up numbers, we would do the following.
chapter = replaceAll(macro("parent_path"), ".*(chapter\\d+)", "$1")
This matches only if there is at least one number after the word "chapter". The double backslash becomes a single backslash when the regular expression is evaluated and \d+ means one or more numbers.
Within a Loop Files operator, the parent_path macro would take values like this within the loop (I'm assuming Windows obviously).
c:\myGiantFolderStructure\mybook\chapter01
c:\myGiantFolderStructure\mybook\chapter02
...
c:\myGiantFolderStructure\mybook\chapter11
The basic idea would be to configure the operator like so.
chapter = replaceAll("%{parent_path}", ".*(chapter.*)", "$1")
This matches the entire macro with a regular expression but locates the word "chapter" and whatever follows it inside a capturing group. This replaces the entire value of the parent_path macro. The result should be a new macro called chapter with values from chapter01 upwards.
Unfortunately, this doesn't work because the backslashes cause trouble. I'm guessing but I think the replaceAll function (and its siblings, replace and concat) try to parse the string within the macro and get confused by treating the backslash as an escape character.
Fortunately, there is a solution: a little known function called macro. This function simply returns the string representation of a named macro.
The expression would then look like this.
chapter = replaceAll(macro("parent_path"), ".*(chapter.*)", "$1")
Knowing that backslashes are processed enables to us work out how to pass them simply by escaping them. If we felt we needed a more sophisticated match inside the capturing group to ensure we picked up numbers, we would do the following.
chapter = replaceAll(macro("parent_path"), ".*(chapter\\d+)", "$1")
This matches only if there is at least one number after the word "chapter". The double backslash becomes a single backslash when the regular expression is evaluated and \d+ means one or more numbers.
Friday 30 August 2013
Pivoting and De-Pivoting
In response to a comment on this post, I made the following process that creates a simple example set, pivots it and then de-pivots it. The end result: the de-pivot result and the original are the same.
The input example set to the de-pivot operation is shown here.

The key parameters for the de-pivot operator are as follows. The first shows that the de-pivot operation will produce examples with an attribute called "name" with values that are nominal and which will not include any missing values from the input example set.

Each example in the result will also contain another attribute and this is dictated by the following parameters.

The regular expression finds all attributes that match. In this case, there are 4.
The de-pivot operation considers each example in the input example set in turn and combines that with the result of the regular expression. The intersection of the example and the matched attribute produces a new attribute value whose name is "value" in this case. For the example here, there are 12 possibilities so the full result would contain 12 examples but this is normally reduced by clearing the check box "keep missings". As mentioned above, one final point is that the "create nominal index" check box must be set in order to get nominal values in the results.
To make the result match the original, there are a couple of sundry operators that rename the values and re-order the attributes.
If I'm honest, I always forget the details of how de-pivoting works so I just adopt the trial and error approach until it looks right.
The input example set to the de-pivot operation is shown here.

The key parameters for the de-pivot operator are as follows. The first shows that the de-pivot operation will produce examples with an attribute called "name" with values that are nominal and which will not include any missing values from the input example set.

Each example in the result will also contain another attribute and this is dictated by the following parameters.

The regular expression finds all attributes that match. In this case, there are 4.
The de-pivot operation considers each example in the input example set in turn and combines that with the result of the regular expression. The intersection of the example and the matched attribute produces a new attribute value whose name is "value" in this case. For the example here, there are 12 possibilities so the full result would contain 12 examples but this is normally reduced by clearing the check box "keep missings". As mentioned above, one final point is that the "create nominal index" check box must be set in order to get nominal values in the results.
To make the result match the original, there are a couple of sundry operators that rename the values and re-order the attributes.
If I'm honest, I always forget the details of how de-pivoting works so I just adopt the trial and error approach until it looks right.
Sunday 28 July 2013
Aggregating attributes with parentheses
I stumbled upon a feature of the Aggregate operator just now that took me far too long to understand; I should have known better. In the spirit of altruism, I hope the following post will save others a bit of time.
It's well known that if attribute names contain parantheses or certain other mathematical symbols, the "Generate Attributes" operator will have problems. Users can get frustrated by this but it's easy to workaround simply by renaming the attributes. To retain backward compatibility I believe it would be extremely disruptive for the RapidMiner product to be changed so we have to live with it.
I discovered that the "Aggregate" operator behaves similarly. The following illustrative process builds a model on the Iris data set and then applies it to the original data (purists will wince at the over-fitting). The process then aggregates by the attributes "label" and "prediction(label)" and counts the number of examples for these combinations. The process also aggregates using a renamed attribute without the parantheses. I have selected "count all combinations" so I am expecting to see 9 rows in the output.
The first output looks like this.

Notice how the "prediction(label)" attribute is missing.
The second output looks like this.

Now we see all 9 expected rows (and continue to wince at the overfitting).
Unfortunately, there is no warning message for the absence in the first case. This probably explains why it took me a while to understand what the problem was. Arguably this could be a bug but I subscribe to the view that the only issues that matter are the ones you don't know about. We know about this one so we can work around it.
As an aside, I have invented a little Groovy script that bulk renames attributes to a standard form but crucially it outputs a second mapping example set which can be stored so the renaming can be reversed later. It's a bit rough and ready so time prevents me from polishing it enough so I can feel good about posting it.
It's well known that if attribute names contain parantheses or certain other mathematical symbols, the "Generate Attributes" operator will have problems. Users can get frustrated by this but it's easy to workaround simply by renaming the attributes. To retain backward compatibility I believe it would be extremely disruptive for the RapidMiner product to be changed so we have to live with it.
I discovered that the "Aggregate" operator behaves similarly. The following illustrative process builds a model on the Iris data set and then applies it to the original data (purists will wince at the over-fitting). The process then aggregates by the attributes "label" and "prediction(label)" and counts the number of examples for these combinations. The process also aggregates using a renamed attribute without the parantheses. I have selected "count all combinations" so I am expecting to see 9 rows in the output.
The first output looks like this.

Notice how the "prediction(label)" attribute is missing.
The second output looks like this.

Now we see all 9 expected rows (and continue to wince at the overfitting).
Unfortunately, there is no warning message for the absence in the first case. This probably explains why it took me a while to understand what the problem was. Arguably this could be a bug but I subscribe to the view that the only issues that matter are the ones you don't know about. We know about this one so we can work around it.
As an aside, I have invented a little Groovy script that bulk renames attributes to a standard form but crucially it outputs a second mapping example set which can be stored so the renaming can be reversed later. It's a bit rough and ready so time prevents me from polishing it enough so I can feel good about posting it.
Sunday 21 July 2013
Scaling attribute values using weights
Here's a process that multiplies each value of an attribute within one example set by a constant in another example set. The constants are specific for each attribute and the process uses weights derived from the example set. In effect, a matrix multiplication is happening.
At a high level, the process works as follows.
At a high level, the process works as follows.
- The Iris data set is used with weights being produced using "Weight By Information Gain"
- These weights are transformed into an example set and stored for later use inside a Loop operator
- A subprocess is used to make sure everything works in the right order (this technique is also used inside the Loop).
- A "Loop Attributes" operator iterates over all attributes and generates a new attribute based on multiplying the existing value by a weight. The attribute name is required to be contained in the weights example set.
- The weight for each example is calculated with a combination of filtering and macro extraction.
Monday 15 July 2013
De-normalizing
Here's a process to reverse the effects of normalizing. The key point is that the normalize operator produces a model that can be applied to an unseen example set. This is important when making the attribute ranges the same in training and test data.
The De-Normalize operator takes a normalized model as input and reverses it so that when this is applied to a normalized example set, a de-normalized version is produced.
In the process, the result is the iris data set which is identical to the original.
The De-Normalize operator takes a normalized model as input and reverses it so that when this is applied to a normalized example set, a de-normalized version is produced.
In the process, the result is the iris data set which is identical to the original.
Tuesday 25 June 2013
Setting outliers to missing
I had some attributes whose values were very out of range and because I was in a hurry I couldn't go back to the source data and eliminate them there. What I wanted to do was to set the value to missing if it was greater than a certain value.
So I used the Generate Attributes operator like so.

In other words if (a1 > 5) then set a1 to missing (by dividing 0 by 0).
It's OK to modify the value of an existing attribute and not create a new attribute at all. I'm sure this used not to work so an enhancement has sneaked in - maybe my memory is playing tricks - I don't mind though - it works.
So I used the Generate Attributes operator like so.

In other words if (a1 > 5) then set a1 to missing (by dividing 0 by 0).
It's OK to modify the value of an existing attribute and not create a new attribute at all. I'm sure this used not to work so an enhancement has sneaked in - maybe my memory is playing tricks - I don't mind though - it works.
Saturday 1 June 2013
Using Groovy to make an arbitrary example set
Here's a Groovy process to make an example set with the number of attributes you want as well as the number of examples.
The process uses two macros to dictate the size of the example set as follows
import com.rapidminer.tools.Ontology;
Integer numberOfAttributes = operator.getProcess().macroHandler.getMacro("numberOfAttributes").toInteger();
Integer numberOfExamples = operator.getProcess().macroHandler.getMacro("numberOfExamples").toInteger();
Attribute[] attributes = new Attribute[numberOfAttributes];
for (i = 0; i < numberOfAttributes; i++) {
name = "att_" + i.toString();
attributes[i] = AttributeFactory.createAttribute(name, Ontology.STRING);
}
MemoryExampleTable table = new MemoryExampleTable(attributes);
DataRowFactory ROW_FACTORY = new DataRowFactory(0);
String[] values = new String[numberOfAttributes];
for (j = 0; j < numberOfExamples; j++){
for (i = 0; i < numberOfAttributes; i++) {
values[i] = 0;
}
DataRow row = ROW_FACTORY.create(values, attributes);
table.addDataRow(row);
}
ExampleSet exampleSet = table.createExampleSet();
return exampleSet;
- numberOfAttributes
- numberOfExamples
These are set in the process context but can easily be defined in other ways.
The attribute names are prefixed with "att_" and the default value is 0. A bit of coding can change this.
Of course, the operators that are already available can be used to recreate this but my personal best is 8 operators to recreate the Groovy script above. I figured a 7 click saving was worth investing a bit of time to get.
Edit: I improved my personal best to 4 operators.
Edit: I improved my personal best to 4 operators.
Thursday 23 May 2013
Finding the next Sunday
I was asked to create a process to find the next Sunday from a given date.
It's a bit clunky but here is a screenshot of the Generate Attributes operator with the various calculations. It shows how much flexibility there is hidden within this operator.

I'm not sure what would happen over a year boundary so it might be worth doing some more checks in this case.
I can think of a couple of other ways this could be done but I might ask for beer or money to work out the details.
It's a bit clunky but here is a screenshot of the Generate Attributes operator with the various calculations. It shows how much flexibility there is hidden within this operator.

I'm not sure what would happen over a year boundary so it might be worth doing some more checks in this case.
I can think of a couple of other ways this could be done but I might ask for beer or money to work out the details.
Sunday 12 May 2013
Saving an example set with the details of the process that created it
Often when there is a lot of data to process, it helps to store intermediate results in the repository.
This allows long multi-step processes to proceed through a series of checkpoints so that if an error occurs, you are not forced to go back to the beginning.
Of course, it does require a certain discipline to be clear what each example set is and where it came from. I often fall into the lazy trap of calling example sets "temp1", "temp2" and so on. This makes it difficult to know what you are dealing with.
To get round this, I created a Groovy script that outputs the entire process XML into a macro. I then use the macro as an annotation that I associate with the example set. I can then store the example set in the repository and if later I want to check how I generated the data, I can simply load it, extract the XML and use it as the basis for recreating the original process in order to help me understand where the data came from.
The Groovy script is only 3 lines long and is shown below.
import com.rapidminer.*;
operator.getProcess().getMacroHandler().addMacro("processXML", operator.getProcess().toString());
return input;
The macro that gets created in this case is called "processXML" and can be used in the normal way.
This allows long multi-step processes to proceed through a series of checkpoints so that if an error occurs, you are not forced to go back to the beginning.
Of course, it does require a certain discipline to be clear what each example set is and where it came from. I often fall into the lazy trap of calling example sets "temp1", "temp2" and so on. This makes it difficult to know what you are dealing with.
To get round this, I created a Groovy script that outputs the entire process XML into a macro. I then use the macro as an annotation that I associate with the example set. I can then store the example set in the repository and if later I want to check how I generated the data, I can simply load it, extract the XML and use it as the basis for recreating the original process in order to help me understand where the data came from.
The Groovy script is only 3 lines long and is shown below.
import com.rapidminer.*;
operator.getProcess().getMacroHandler().addMacro("processXML", operator.getProcess().toString());
return input;
The macro that gets created in this case is called "processXML" and can be used in the normal way.
Tuesday 7 May 2013
Built-in macros
There are a number of pre-defined macros that can be used within RapidMiner. I keep forgetting the details of these so I decided to write them down once and for all.
These do not show up in the macro view but it is possible to use them like other macros.
I copied the following text from the version 4.6 RapidMiner documentation...
%{a} is replaced by the number of times the operator was applied.
%{b} is replaced by the number of times the operator was applied plus one, i.e. %a + 1. This is a shortcut for %p[1].
%{p[number }] is replaced by the number of times the operator was applied plus the given number, i.e. %a + number. (note - this should be %{p[N]}
%{t} is replaced by the system time.
%{n} is replaced by the name of the operator.
%{c} is replaced by the class of the operator.
%{%} becomes %.
%{process_name} becomes the name of the process file (without path and extension).
%{process_file} becomes the name of the process file (with extension).
%{process_path} becomes the path of the process file.
I've tried these - I can't get %{p[n]} to work nor all the ones starting with "process_". No matter, the others work.
Here is a screenshot of a Generate Macro process that uses them.

Here is a screenshot of the results from the Macro view.

These do not show up in the macro view but it is possible to use them like other macros.
I copied the following text from the version 4.6 RapidMiner documentation...
%{a} is replaced by the number of times the operator was applied.
%{b} is replaced by the number of times the operator was applied plus one, i.e. %a + 1. This is a shortcut for %p[1].
%{p[number }] is replaced by the number of times the operator was applied plus the given number, i.e. %a + number. (note - this should be %{p[N]}
%{t} is replaced by the system time.
%{n} is replaced by the name of the operator.
%{c} is replaced by the class of the operator.
%{%} becomes %.
%{process_name} becomes the name of the process file (without path and extension).
%{process_file} becomes the name of the process file (with extension).
%{process_path} becomes the path of the process file.
I've tried these - I can't get %{p[n]} to work nor all the ones starting with "process_". No matter, the others work.
Here is a screenshot of a Generate Macro process that uses them.

Here is a screenshot of the results from the Macro view.

Wednesday 24 April 2013
Operators that deserve to be better known: part VI
Remove Unused Values
This operator removes the possible nominal values that an attribute can have but which are not used in the example set. This can happen if the example set has been sampled or filtered.
As an example, if an attribute is called Fruit and has possible values Apple, Banana, Orange or Pear and some filtering is done to remove all except Apple, the possible values for Fruit can still be the other values but there are no examples in the filtered example set that use these values. This can be seen in the meta data view for the example set.
This is not normally a problem but if you have a giant data set with lots of nominal values the resulting example set can be slow to process even after sampling or filtering. A particular case would be where each attribute value is a line of text. I had a situation like this where I sampled 2 million rows down to 100 in order to get my process working only to find that the seemingly small 100 row example set was taking a long time to load.
This is easily resolved by using the Remove Unused Values operator (and as an aside you could also simply convert the polynominal attribute to be of type text in the case of text processing).
This operator removes the possible nominal values that an attribute can have but which are not used in the example set. This can happen if the example set has been sampled or filtered.
As an example, if an attribute is called Fruit and has possible values Apple, Banana, Orange or Pear and some filtering is done to remove all except Apple, the possible values for Fruit can still be the other values but there are no examples in the filtered example set that use these values. This can be seen in the meta data view for the example set.
This is not normally a problem but if you have a giant data set with lots of nominal values the resulting example set can be slow to process even after sampling or filtering. A particular case would be where each attribute value is a line of text. I had a situation like this where I sampled 2 million rows down to 100 in order to get my process working only to find that the seemingly small 100 row example set was taking a long time to load.
This is easily resolved by using the Remove Unused Values operator (and as an aside you could also simply convert the polynominal attribute to be of type text in the case of text processing).
Sunday 21 April 2013
Rename by generic names and creating a model: which attributes are used?
The Rename by Generic Names operator can be used to rename attributes so they follow a simple naming convention with a generic stem and an incrementing counter. You would use this for example to get rid of punctuation or mathematical symbols that would prevent the Generate Attributes operator from working.
As an example, if you had regular attributes like
The rename would yield something like
The other day, I stumbled on an odd side effect of this when building linear regression models on renamed attributes. Fortunately, I don't think it's a problem but there's a workaround anyway.
Firstly then, here is an ultra simple process that builds a linear regression model on some fake data which has had its attributes renamed generically. The example set it produces looks like this.

The regression model looks like this.

How odd; the names of the attributes before the rename have been used to describe the model. This causes confusion but as far as I can tell the models and weights seem to be fine when they are used in a process. The names are in fact still in the example set and can be seen from the Meta Data View by showing the Constructions column. This points to using the Materialize Data operator as a workaround. By adding this operator just after the rename, the model comes out as follows.

Less confusing for a human.
As an example, if you had regular attributes like
- Average(height)
- Minimum(height)
- Variance(height)
The rename would yield something like
- att1
- att2
- att3
This is more usable but is less understandable.
The other day, I stumbled on an odd side effect of this when building linear regression models on renamed attributes. Fortunately, I don't think it's a problem but there's a workaround anyway.
Firstly then, here is an ultra simple process that builds a linear regression model on some fake data which has had its attributes renamed generically. The example set it produces looks like this.

The regression model looks like this.
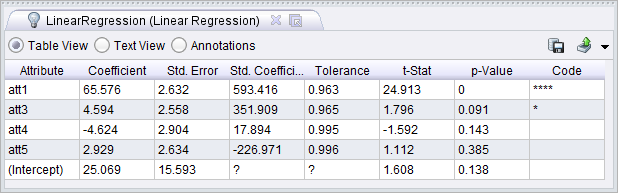
How odd; the names of the attributes before the rename have been used to describe the model. This causes confusion but as far as I can tell the models and weights seem to be fine when they are used in a process. The names are in fact still in the example set and can be seen from the Meta Data View by showing the Constructions column. This points to using the Materialize Data operator as a workaround. By adding this operator just after the rename, the model comes out as follows.

Less confusing for a human.
Monday 15 April 2013
Counting words in lots of documents
In response to a request contained in a comment for this post, I've modified the process to count total words and unique words for multiple files.
It does this by using the Loop Files operator to iterate over all the files in a folder.

The Loop operator outputs a collection and the Append operator joins them into a single example set.
Inside the Loop operator, the Read Document operator reads the current file and converts it into a document.

Words and unique words are counted as before and the final operator adds an attribute based on the file name contained in the macro provided by the outer Loop operator.
An example result looks like this.

Download the process here and set the directory and filter parameters of the Loop Files operator to the location you want.
It does this by using the Loop Files operator to iterate over all the files in a folder.

The Loop operator outputs a collection and the Append operator joins them into a single example set.
Inside the Loop operator, the Read Document operator reads the current file and converts it into a document.

Words and unique words are counted as before and the final operator adds an attribute based on the file name contained in the macro provided by the outer Loop operator.
An example result looks like this.

Download the process here and set the directory and filter parameters of the Loop Files operator to the location you want.
Friday 5 April 2013
Finding text needles in document haystacks
I had to find how many times a sentence occurred within a large set of documents recently and rather than use a search tool or write some software I used RapidMiner.
Here are the bare bones XML of the process to do this with pictures to help explain (the numbers are shown by clicking on the operator execution order within the RapidMiner GUI).

The basic elements are

The tokenize operator simply uses anything but alphanumeric and space as a token boundary. This has the effect of creating each of the provided phrases as valid tokens. The replace tokens operator replaces all occurrences of space with underscore to match what the n-gram generation operator will produce later.
The final process documents operator (labelled 4) contains the following operators.

This tokenizes but by virtue of using the word list from the previous operator, only these will be considered in the final output example set once the generate n-gram operator has combined tokens together.
The end result is shown below.

The end result shows how many times the text appears in the document.
One advantage this approach has is that it seems to execute very quickly.
Here are the bare bones XML of the process to do this with pictures to help explain (the numbers are shown by clicking on the operator execution order within the RapidMiner GUI).

The basic elements are
- A document is created to contain the text-to-look-for - the text needles.
- A word list is created from these using the process documents operator.
- A document containing text to search through is created - the document haystack.
- The document is processed and only the provided word list items are included in the resulting document vector. This is set to output term-occurrences so the end result is a count of the number of times the text-to-look-for appeared in the document.
There are some points to note.
The text-to-look for is shown as the parameters to the first create document operator (labelled 1 above) shown here.

The text-to-look for is shown as the parameters to the first create document operator (labelled 1 above) shown here.

The document to look in contains a fragment of text copied from page 391 of the RapidMiner manual (labelled 3 above).

The first process documents operator (labelled 2) itself contains the following operators.

The first process documents operator (labelled 2) itself contains the following operators.

The tokenize operator simply uses anything but alphanumeric and space as a token boundary. This has the effect of creating each of the provided phrases as valid tokens. The replace tokens operator replaces all occurrences of space with underscore to match what the n-gram generation operator will produce later.
The final process documents operator (labelled 4) contains the following operators.

This tokenizes but by virtue of using the word list from the previous operator, only these will be considered in the final output example set once the generate n-gram operator has combined tokens together.
The end result is shown below.
One advantage this approach has is that it seems to execute very quickly.
{kind=link}
Wednesday 6 March 2013
Append converts text attributes to polynominal
I stumbled on a foible of the "Append" operator the other day.
Attributes of type text in the input example sets are converted to type polynominal in the output example set. This has the effect that subsequent document processing will ignore the attributes.
It took a few minutes for me to work out why so I hope this will save any others these minutes. It's easy to fix, simply use the operator "Convert Nominal to Text" on the output example set.
Edit: this has been fixed in the latest release.I didn't think it was dreadfully serious but thanks to the RM developer chaps anyway.
Attributes of type text in the input example sets are converted to type polynominal in the output example set. This has the effect that subsequent document processing will ignore the attributes.
It took a few minutes for me to work out why so I hope this will save any others these minutes. It's easy to fix, simply use the operator "Convert Nominal to Text" on the output example set.
Edit: this has been fixed in the latest release.I didn't think it was dreadfully serious but thanks to the RM developer chaps anyway.
Wednesday 13 February 2013
Sorting discretized examples in the order nature intended
Using the "Discretize" operators puts examples into different nominal bins depending on the value of an attribute. When using the long form of the name type, the possible nominal value names are of this general format "rangeN [x-y]"
N starts at 1 and ends at whatever the largest bin number is. The N is not preceded by any leading zeros so this means that when sorted, range10 comes before range2. When using the histogram plotter this is OK because the nominal values have an implicit order that gets used. When using the advanced plotter however, a histogram comes out wrong.
Here's a histogram, produced using the advanced plotter, showing the original ordering. The data is 10,000 examples generated by multiplying 5 random numbers together and normalizing to the range 0 to 1.
 As can be seen, the ordering of the bins is not in the same numerical order of the underlying numerical values.
As can be seen, the ordering of the bins is not in the same numerical order of the underlying numerical values.
This can be fixed by using regular expressions and the "Replace" operator.
I'm not enough of a regular expression ninja to do this in one operator so I had to use two.
So, in the first "Replace" operator, set the "replace what" field to
In the second "Replace" operator, set the replace field to
Be aware that you might have to tweak these numbers if the number of names is different in your case.
The end result is then a histogram like this

Now the ordering is the same as the implied numerical ordering.
N starts at 1 and ends at whatever the largest bin number is. The N is not preceded by any leading zeros so this means that when sorted, range10 comes before range2. When using the histogram plotter this is OK because the nominal values have an implicit order that gets used. When using the advanced plotter however, a histogram comes out wrong.
Here's a histogram, produced using the advanced plotter, showing the original ordering. The data is 10,000 examples generated by multiplying 5 random numbers together and normalizing to the range 0 to 1.

This can be fixed by using regular expressions and the "Replace" operator.
I'm not enough of a regular expression ninja to do this in one operator so I had to use two.
So, in the first "Replace" operator, set the "replace what" field to
range(\d+.*)and set the replace by field to
range0000$1This will change all the values to have leading zeros inserted before the number within the value.
In the second "Replace" operator, set the replace field to
range0+(\d{4})(.*)and set the replace by field to
range$1$2This ensures that all the numeric parts of the range name are of the same length and are preceded by at least one leading 0.
Be aware that you might have to tweak these numbers if the number of names is different in your case.
The end result is then a histogram like this

Now the ordering is the same as the implied numerical ordering.
Tuesday 22 January 2013
New in 5.3: Annotation operators
I just downloaded RapidMiner 5.3 and some shiny new things caught my eye. One thing I noticed was some new operators that allow annotations to be created within a process. Annotations are associated with IOobjects like data, cluster models, weights and you can store any free text you like with them. The annotation is retained with the IOobject if it is stored in the repository. With these new operators, it means you could add generated information such as a timestamp, the time taken to process the data or any other environmental information.
I have a lot of data lying around in my repositories and it would be very helpful if I had created a simple annotation to give me some clue what the data is and where it came from. Now I can.
I have a lot of data lying around in my repositories and it would be very helpful if I had created a simple annotation to give me some clue what the data is and where it came from. Now I can.
Subscribe to:
Posts (Atom)