Remove Unused Values
This operator removes the possible nominal values that an attribute can have but which are not used in the example set. This can happen if the example set has been sampled or filtered.
As an example, if an attribute is called Fruit and has possible values Apple, Banana, Orange or Pear and some filtering is done to remove all except Apple, the possible values for Fruit can still be the other values but there are no examples in the filtered example set that use these values. This can be seen in the meta data view for the example set.
This is not normally a problem but if you have a giant data set with lots of nominal values the resulting example set can be slow to process even after sampling or filtering. A particular case would be where each attribute value is a line of text. I had a situation like this where I sampled 2 million rows down to 100 in order to get my process working only to find that the seemingly small 100 row example set was taking a long time to load.
This is easily resolved by using the Remove Unused Values operator (and as an aside you could also simply convert the polynominal attribute to be of type text in the case of text processing).
Wednesday 24 April 2013
Sunday 21 April 2013
Rename by generic names and creating a model: which attributes are used?
The Rename by Generic Names operator can be used to rename attributes so they follow a simple naming convention with a generic stem and an incrementing counter. You would use this for example to get rid of punctuation or mathematical symbols that would prevent the Generate Attributes operator from working.
As an example, if you had regular attributes like
The rename would yield something like
The other day, I stumbled on an odd side effect of this when building linear regression models on renamed attributes. Fortunately, I don't think it's a problem but there's a workaround anyway.
Firstly then, here is an ultra simple process that builds a linear regression model on some fake data which has had its attributes renamed generically. The example set it produces looks like this.

The regression model looks like this.

How odd; the names of the attributes before the rename have been used to describe the model. This causes confusion but as far as I can tell the models and weights seem to be fine when they are used in a process. The names are in fact still in the example set and can be seen from the Meta Data View by showing the Constructions column. This points to using the Materialize Data operator as a workaround. By adding this operator just after the rename, the model comes out as follows.

Less confusing for a human.
As an example, if you had regular attributes like
- Average(height)
- Minimum(height)
- Variance(height)
The rename would yield something like
- att1
- att2
- att3
This is more usable but is less understandable.
The other day, I stumbled on an odd side effect of this when building linear regression models on renamed attributes. Fortunately, I don't think it's a problem but there's a workaround anyway.
Firstly then, here is an ultra simple process that builds a linear regression model on some fake data which has had its attributes renamed generically. The example set it produces looks like this.

The regression model looks like this.
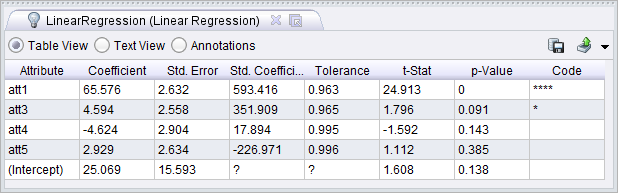
How odd; the names of the attributes before the rename have been used to describe the model. This causes confusion but as far as I can tell the models and weights seem to be fine when they are used in a process. The names are in fact still in the example set and can be seen from the Meta Data View by showing the Constructions column. This points to using the Materialize Data operator as a workaround. By adding this operator just after the rename, the model comes out as follows.

Less confusing for a human.
Monday 15 April 2013
Counting words in lots of documents
In response to a request contained in a comment for this post, I've modified the process to count total words and unique words for multiple files.
It does this by using the Loop Files operator to iterate over all the files in a folder.

The Loop operator outputs a collection and the Append operator joins them into a single example set.
Inside the Loop operator, the Read Document operator reads the current file and converts it into a document.

Words and unique words are counted as before and the final operator adds an attribute based on the file name contained in the macro provided by the outer Loop operator.
An example result looks like this.

Download the process here and set the directory and filter parameters of the Loop Files operator to the location you want.
It does this by using the Loop Files operator to iterate over all the files in a folder.

The Loop operator outputs a collection and the Append operator joins them into a single example set.
Inside the Loop operator, the Read Document operator reads the current file and converts it into a document.

Words and unique words are counted as before and the final operator adds an attribute based on the file name contained in the macro provided by the outer Loop operator.
An example result looks like this.

Download the process here and set the directory and filter parameters of the Loop Files operator to the location you want.
Friday 5 April 2013
Finding text needles in document haystacks
I had to find how many times a sentence occurred within a large set of documents recently and rather than use a search tool or write some software I used RapidMiner.
Here are the bare bones XML of the process to do this with pictures to help explain (the numbers are shown by clicking on the operator execution order within the RapidMiner GUI).

The basic elements are

The tokenize operator simply uses anything but alphanumeric and space as a token boundary. This has the effect of creating each of the provided phrases as valid tokens. The replace tokens operator replaces all occurrences of space with underscore to match what the n-gram generation operator will produce later.
The final process documents operator (labelled 4) contains the following operators.

This tokenizes but by virtue of using the word list from the previous operator, only these will be considered in the final output example set once the generate n-gram operator has combined tokens together.
The end result is shown below.

The end result shows how many times the text appears in the document.
One advantage this approach has is that it seems to execute very quickly.
Here are the bare bones XML of the process to do this with pictures to help explain (the numbers are shown by clicking on the operator execution order within the RapidMiner GUI).

The basic elements are
- A document is created to contain the text-to-look-for - the text needles.
- A word list is created from these using the process documents operator.
- A document containing text to search through is created - the document haystack.
- The document is processed and only the provided word list items are included in the resulting document vector. This is set to output term-occurrences so the end result is a count of the number of times the text-to-look-for appeared in the document.
There are some points to note.
The text-to-look for is shown as the parameters to the first create document operator (labelled 1 above) shown here.

The text-to-look for is shown as the parameters to the first create document operator (labelled 1 above) shown here.

The document to look in contains a fragment of text copied from page 391 of the RapidMiner manual (labelled 3 above).

The first process documents operator (labelled 2) itself contains the following operators.

The first process documents operator (labelled 2) itself contains the following operators.

The tokenize operator simply uses anything but alphanumeric and space as a token boundary. This has the effect of creating each of the provided phrases as valid tokens. The replace tokens operator replaces all occurrences of space with underscore to match what the n-gram generation operator will produce later.
The final process documents operator (labelled 4) contains the following operators.

This tokenizes but by virtue of using the word list from the previous operator, only these will be considered in the final output example set once the generate n-gram operator has combined tokens together.
The end result is shown below.
One advantage this approach has is that it seems to execute very quickly.
{kind=link}
Subscribe to:
Posts (Atom)